Как архивировать Веб
•
Александр Котов
•
785 слов
веб-архив
архивирование
internet archive
archive.today
archivebox
web
веб
сервисы
self-hosting
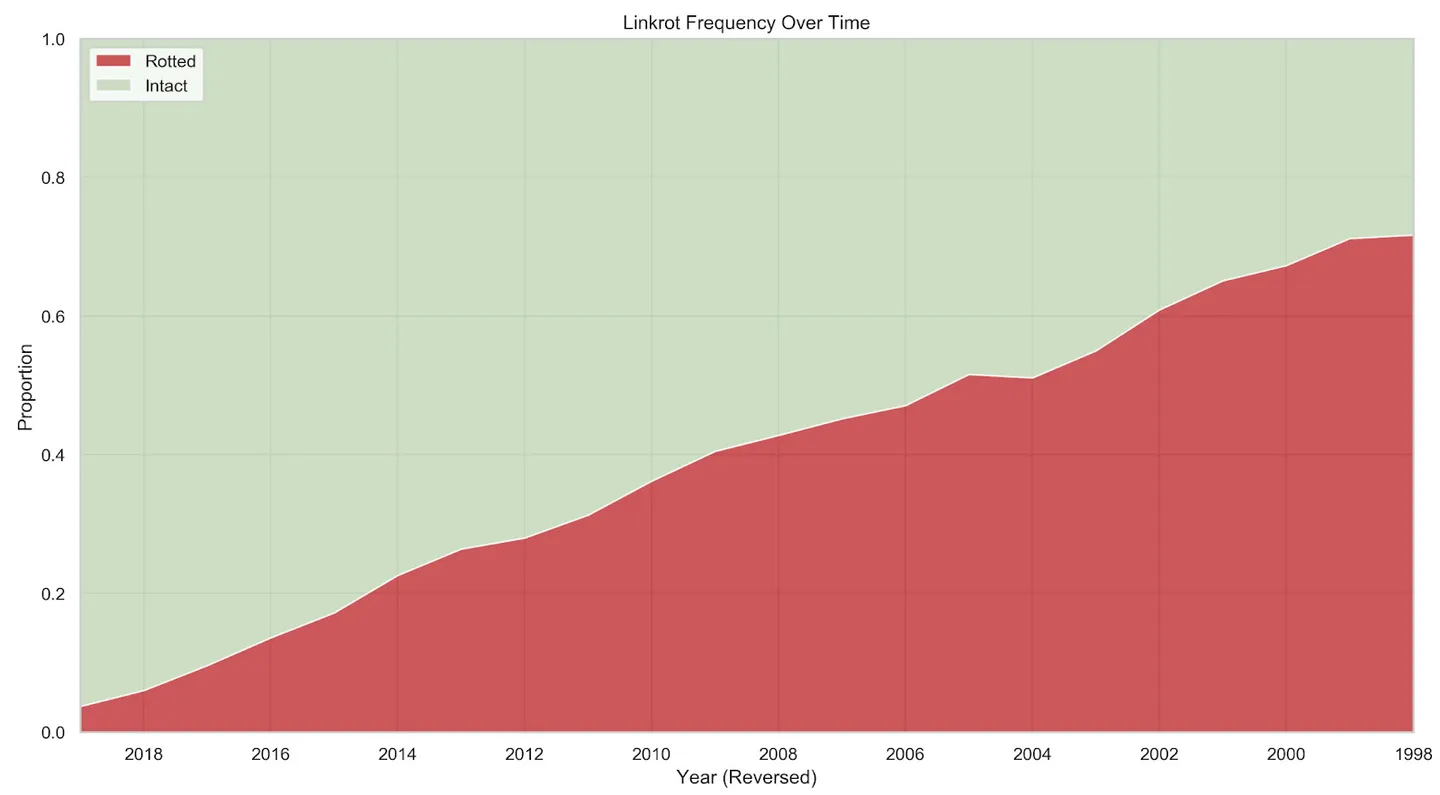
Целью архивирования Веба является решение проблемы вымирания ссылок[1] — ситуации, когда ссылки из закладок, веб-страниц, статей, судебных решений и других мест больше не указывают на изначальную информацию. Они могут вовсе не работать, вести на что-то постороннее или на искажённую информацию. Продолжительность жизни ссылок зависит от разных факторов, однако основным является время — чем старше ссылка, тем больше вероятность того, что она будет нерабочей. Есть исследование, которое показывает, что в статьях издания The New York Times от 2018 года нерабочими являются 6% ссылок, а в статьях от 1998 года — 72%.[2]
На проблему вымирания ссылок обратили внимание ещё в девяностые годы XX века. Государства, например, возложили обязанность архивирования источников на библиотеки. Для нужд частных лиц и компаний были созданы некоммерческие организации, самой известной из которых является Internet Archive[3]. Изначально каждая организация использовала собственные инструменты и форматы. В дальнейшем они смогли объединить усилия и разработать стандарты, такие как WARC[4], а также много совместимого ПО.[5][6][7]
Несмотря на некоторую стандартизацию и наличие зрелых инструментов, архивирование Веба по-прежнему является довольно сложной задачей. Веб-сервер может ограничивать работу автоматизированных систем, выдавая не то содержимое, которое видит обычный пользователь веб-браузера, а ошибку или постороннюю информацию. Содержимое архивируемой веб-страницы может создаваться динамически с помощью JavaScript. Воссоздание страницы в таком случае требует воспроизведения ответов на запросы к API, что может быть проблематично. Исполнение JavaScript влечёт проблемы с безопасностью. Впрочем, порой веб-страницы в архиве становятся более читаемыми, чем в оригинале. Например, с них могут пропадать требование о приобретении доступа за оплату (paywall) и различные отвлекающие всплывающие окна.
Существующие проекты архивирования Веба решают эти проблемы по-разному. Но что делать рядовому пользователю, который не готов посвящать значительную часть своего времени изучению всех инструментов и форматов? На примере нужд нашего веб-сайта я рассмотрю несколько относительно простых в использовании инструментов, как сторонних, так и тех, которые можно администрировать самостоятельно.
Wayback Machine
Wayback Machine[8] от Internet Archive[3] — это старейший и крупнейший публичный инструмент для архивирования Веба, не требующий даже регистрации. Он управляется некоммерческой организацией, расположенной в США и получающей финансирование через пожертвования, гранты и предоставление услуг. Архив включает 735 миллиардов веб-страниц, более 99 петабайт информации.[9] Благодаря доступности и популярности инструмента Wayback Machine считается де-факто стандартом для архивирования Веба, и почти любая более-менее популярная страница скорее всего будет присутствовать в архиве в нескольких версиях.
Wayback Machine использует формат WARC[4] и пытается восстановить веб-страницу в оригинальном виде, в том числе исполняя JavaScript на стороне пользователя. Для некоторых динамических веб-сайтов это может порождать более работоспособные копии, но часто бывает наоборот, особенно когда владельцы веб-сайта пытаются ограничить свободный доступ к информации. Так, страницы Reddit и Twitter сохранить не получится, а статьи The New York Times скрыты требованием о приобретении доступа за оплату. Также Internet Archive, не желая стать жертвой судебных исков, удаляет материалы по запросу автора, что делает этот сервис не совсем надёжным.
Сейчас Internet Archive испытывает трудности из-за юридического давления правообладателей.[10] Если вы цените тот вклад, который организация вносит в доступность информации, то можете поддержать[11] её финансово.
archive.today
archive.today[12] был запущен в 2012 году. Его авторы и владельцы неизвестны. Возможно, это всего один человек. Из-за этого нельзя говорить о каких-то гарантиях, и я не рекомендую этот сервис как основной. Однако владельцы исправно поддерживают работоспособность сайта и активно взаимодействуют с сообществом, что делает его отличным инструментом в дополнение к Wayback Machine. Он тоже не требует регистрации и является довольно популярным.
Сервис сохраняет только основные элементы веб-страницы, такие как гипертекст, стили и изображения. Архивная копия получается полностью статической. Однако JavaScript исполняется при архивировании, что позволяет частично воспроизводить сложные динамические веб-сайты, такие как Reddit и Twitter. Статьи The New York Times сохраняются целиком, что позволяет просматривать их без подписки. Владельцы сервиса неохотно удаляют содержимое, что привело к его блокировке в некоторых странах.[13]
ArchiveBox
Сторонние сервисы — это просто и удобно, но вы не управляете вашими данными, и нет абсолютных гарантий их сохранности. Программа ArchiveBox[14] позволяет довольно легко поднять свой собственный веб-архив. Она сохраняет страницы сразу в нескольких форматах (среди которых есть и WARC[4]), имеет удобный веб-интерфейс и работает на настольном компьютере, не требуя наличия постоянного сервера. Главный концептуальный недостаток — большой размер всего архива из-за отсутствия дедупликации. Так, у меня 37 страниц занимают 273 мегабайта — это по 7.4 мегабайта на страницу, что особенно плохо, учитывая, что значительная часть из этих страниц принадлежат одному веб-сайту (Википедии). Поэтому программа подходит только для небольших личных архивов, с ростом объёмов данных придётся переходить на более сложные решения. Впрочем, информацию из ArchiveBox можно будет перенести.
Программа написана не очень качественно и безопасно. Некоторые форматы могут воспроизводить JavaScript, при этом нет механизма разделения интерфейсов администрирования и просмотра архивных копий. Поэтому я не рекомендую запускать сам ArchiveBox на сервере. Вместо этого можно экспортировать локальную копию архива как статический веб-сайт. Именно такой подход я и использую, примеры можно увидеть в списке источников внизу данной статьи. Локально же запускать программу проще всего с помощью Docker Compose.
Ссылки
- Wikipedia: Вымирание ссылок (arch.causa-arcana.com, web.archive.org, archive.today)
- New research shows how many important links on the web get lost to time (arch.causa-arcana.com, web.archive.org, archive.today)
- Internet Archive — Digital Library of Free & Borrowable Books, Movies, Music & Wayback Machine
- Wikipedia: WARC (file format) (arch.causa-arcana.com, web.archive.org, archive.today)
- Wikipedia: Архивирование веб-сайтов (arch.causa-arcana.com, web.archive.org, archive.today)
- Archiving web sites (arch.causa-arcana.com, web.archive.org, archive.today)
- Архивирование веб-сайтов (arch.causa-arcana.com, web.archive.org, archive.today)
- Internet Archive: Wayback Machine
- Internet Archive: About IA (arch.causa-arcana.com, web.archive.org)
- Record Labels Hit Internet Archive With New $400m+ Copyright Lawsuit (arch.causa-arcana.com, web.archive.org, archive.today)
- Internet Archive: Donate to the Internet Archive!
- archive.today — create a copy of a webpage that will always be up
- Wikipedia: archive.today (arch.causa-arcana.com, web.archive.org, archive.today)
- ArchiveBox — Open source self-hosted web archiving. Takes URLs/browser history/bookmarks/Pocket/Pinboard/etc., saves HTML, JS, PDFs, media, and more... (arch.causa-arcana.com, web.archive.org, archive.today)